




It is well known in the Data Science world that building predictive models is a small part of a data scientist’s daily work. In fact, based on this report by Forbes, it is estimated that 80% of the time is spent exploring the data, cleaning it, and doing feature engineering. Although this amount of time varies depending on the use-case industry, the data type, and many other factors, the preprocessing phase remains highly time-consuming.
Usually, the job is done manually working on a Jupyter Notebook environment and using programming languages like Python, R, or SQL, only to mention the most popular ones. This being said, the data preparation step is often a challenging one, requiring advanced data engineering skills. Depending on the Data Scientist’s profile, these steps may be more or less complicated and are rarely performed at scale.
Based on their internal structure, some companies have this part of the work done by Data Engineers as they have the appropriate skills to handle the data properly. But still, the collaboration between Data Scientists and Engineers often creates several iterations that can turn into an endless cycle in the worst-case scenario.
With this in mind, AWS has presented a new service to facilitate the data preparation, and thus, AWS Glue DataBrew was launched at the 2020 re:Invent.
What is AWS Glue DataBrew
DataBrew is a graphical interface-based data preparation tool that allows data scientists/analysts to explore, analyze and transform raw data without writing any lines of code. It is part of AWS Glue, and like its parent, is a scalable and fully managed service. The user-friendly interface makes data preparation easy and convenient.
Setting up
Datasets
The dataset can come from various sources, such as an S3 bucket, local machine, Redshift Warehouse, or third-party resources like Salesforce.
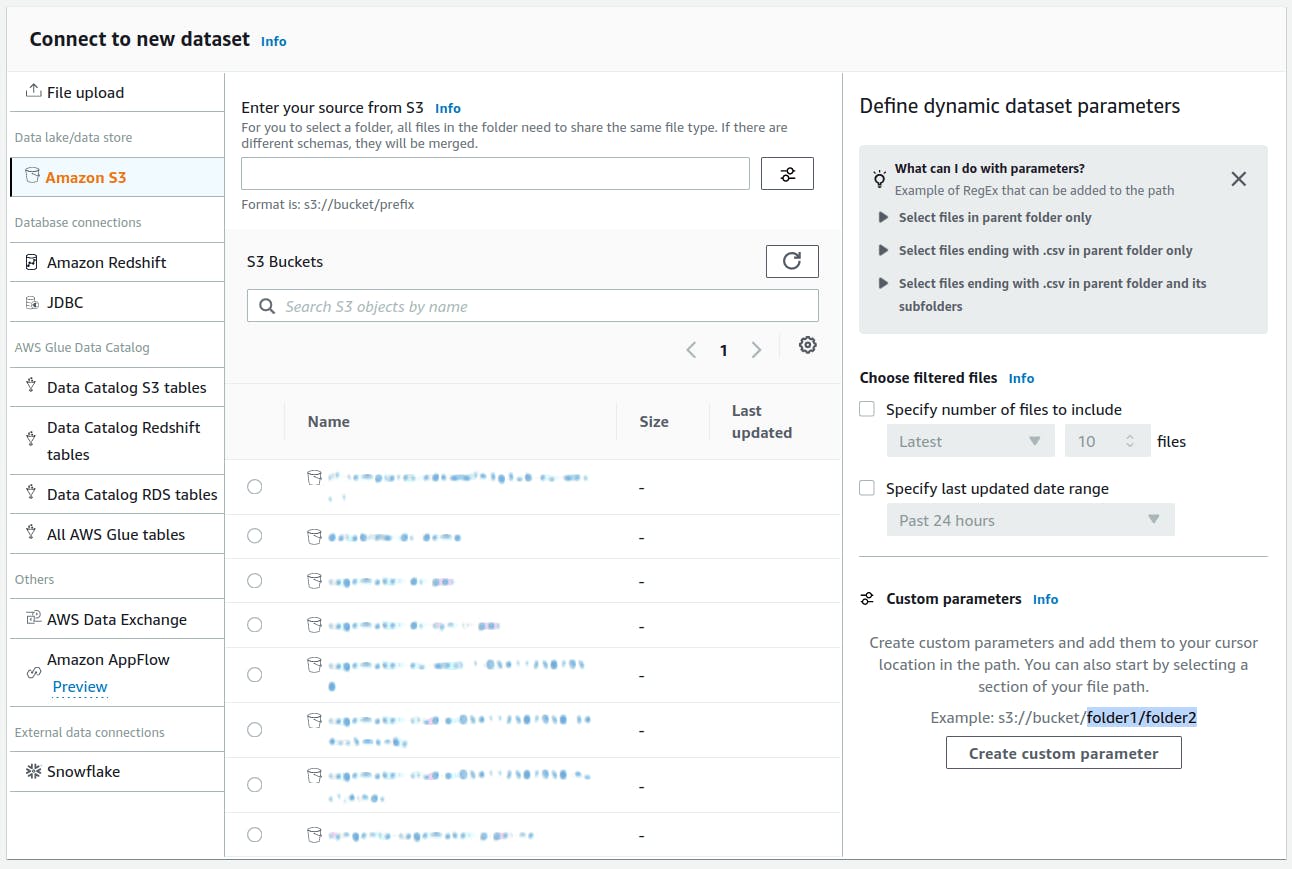
Once you import a dataset, it gets stored on an S3 bucket and is automatically registered in the dataset section. Datasets can be imported to multiple projects. DataBrew also offers some sample datasets that can be used to play and experiment with the environment.
Projects
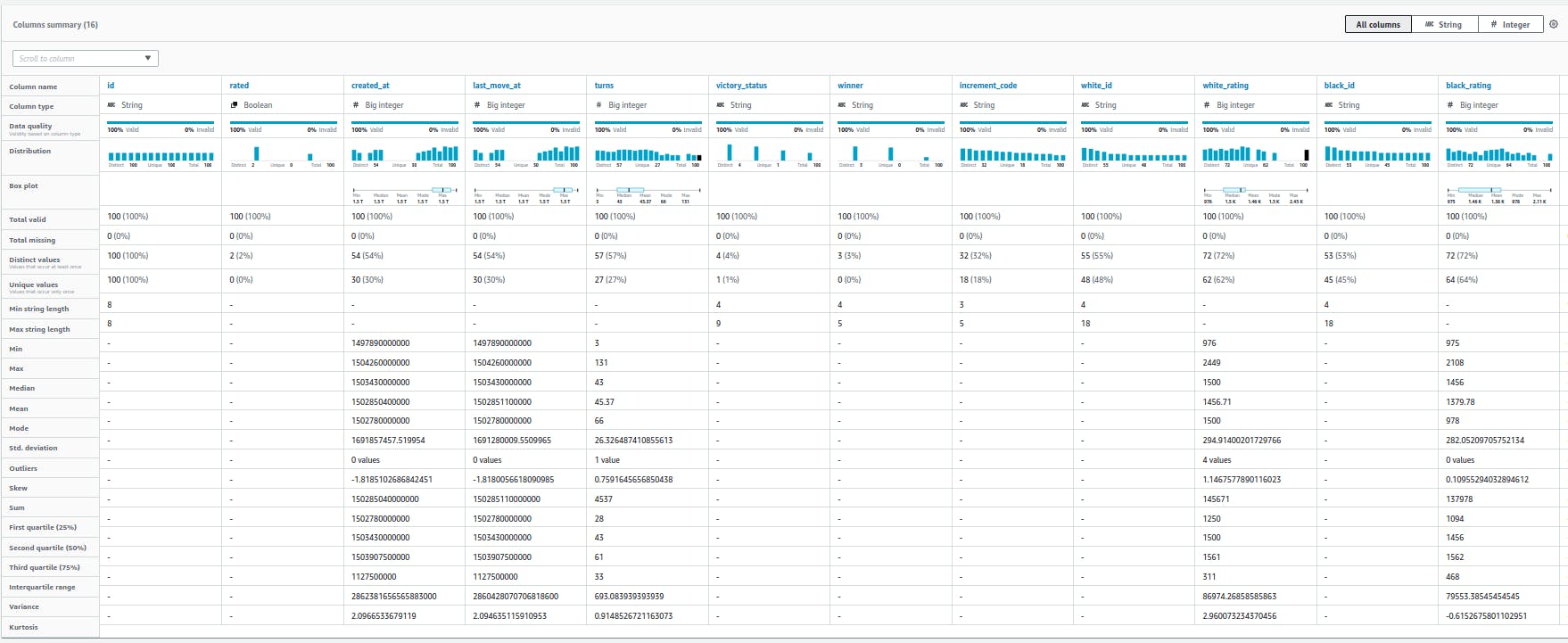
Project is the primary working environment. You can import a dataset inside a project and start processing your data. For performance matters, transformations are only applied to a sample of the dataset. The user can define the size of the sample. When you start a project, AWS takes care of provisioning computing resources, initiates a preprocessing session, imports the dataframe, and infers basic statistics. By clicking on the Schema button, you can have a perspective on data types, data distribution, boxplots, and some info on valid/missing values. DataBrew comes with an extensive set of built-in transformations that cover each step of data processing: Cleaning (e.g., removing duplicates rows and/or null values), transforming (e.g., converting to date formats and groupings), and feature engineering (e.g., one-hot encoding).
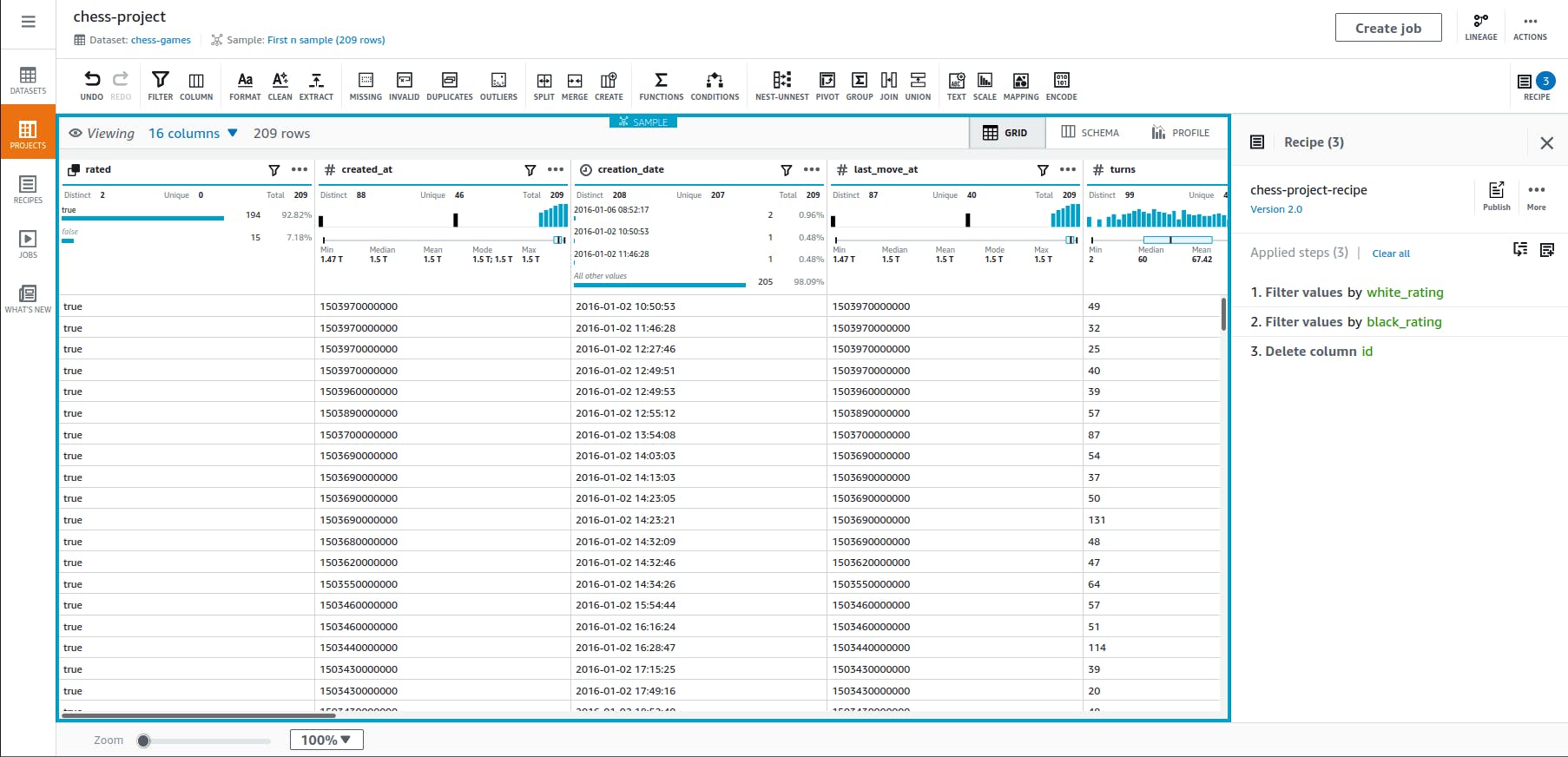
Recipes
Recipes are the core feature of AWS Glue DataBrew. Each recipe consists of a list of sequential data transformations that the user will perform using the interface. Best of all, recipes support versioning, meaning you can have multiple recipes for a project, each with different steps to manipulate data. Recipes can also be shared between people and even across accounts. These features provide a replicable, reusable and dynamic capability to preprocess data.
Jobs
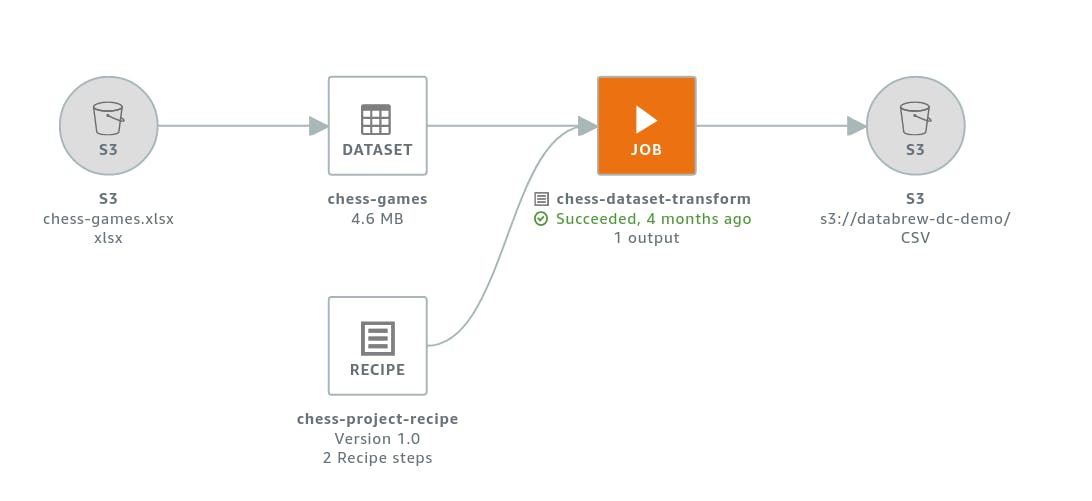
As mentioned above, when creating a project and adding recipes, we only work with a sample of the data. Once the recipe is created, we can apply it to the whole dataset by creating a job. DataBrew will transform the entire dataset and store preprocessed data in a specified S3 bucket. If the dataset is large, it will be partitioned into multiple files.
Data Profiling
Data Profiling is another feature of DataBrew. It provides a description of data quality and statistical indices of the whole dataset or a sample. Data Profiling also provides a correlation table by which correlated features can be observed at a glance.
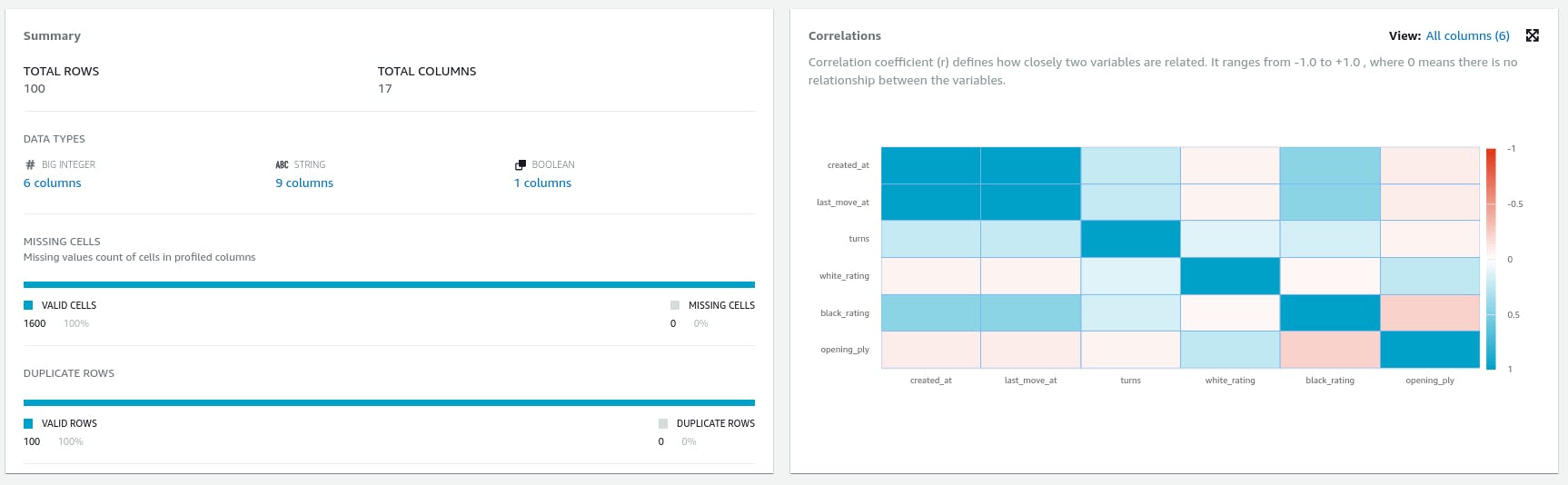
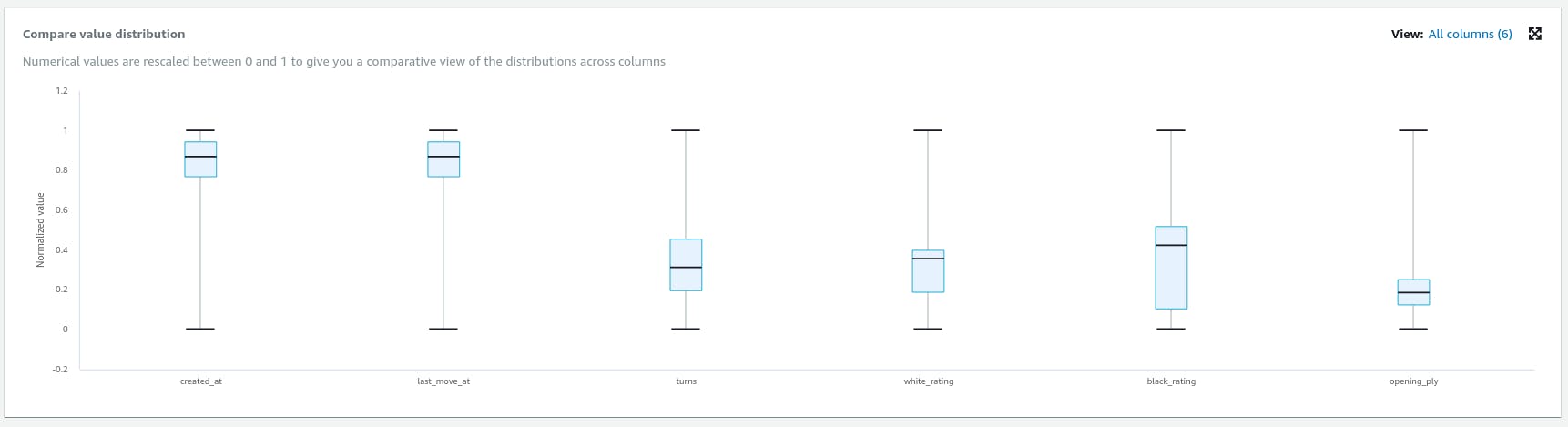
Profiling also provides distribution views.
Security
Like other AWS tools, DataBrew follows AWS Shared Responsibility Model. Amazon takes responsibility for the security of the cloud, while the user is partially or entirely responsible for the security in the cloud. For example, you can use encryption for data at rest or in transit. Stored data is resilient as it can be stored in multiple Availability Zones.
Benefits
By leveraging the 250 ready-made transformations available in the graphical interface, data engineers/scientists/analysts can reduce the preprocessing time by 80% (based on AWS’s claim). DataBrew particularly helps when collaborators are not on the same page regarding their preprocessing tool. DataBrew doesn’t require knowledge of programming languages, as it is a point-and-click tool. DataBrew also provides some intelligent suggestions to speed up the preprocessing. Furthermore, it comes with some tools for preprocessing text data used in Natural Language Processing tasks. If you care about data security, using DataBrew, like other AWS tools, provides many benefits over wrangling data locally.
Limitations
By now, you understand that DataBrew is a high-level tool for wrangling data. This fact takes away some of the flexibility from those who are used to working with popular libraries like pandas. Although DataBrew offers some quick graphs for visualizations, you may find yourself unable to create custom visualizations. On the other hand, DataBrew is an online tool, and one can’t utilize it offline on a local machine. Of course, as mentioned in the introduction, DataBrew is newly launched, and these limitations may be resolved in the future.
Pricing
Projects
Each 30 minutes of a project session costs $1. For example, if you use two project sessions for an hour, the total cost would be:
2 * $1 * 60/30 = $4
Jobs
The price of a job is based on the number of nodes utilized. By default, DataBrew uses five nodes for a job. Each node provides 4 virtual CPUs and 16 GB of memory and costs $0.48 per hour. You will be billed for the minutes that your job lasts. For example, if the job takes 10 minutes and uses five nodes, you will be charged as follows:
5 * $0.48 * 10 / 60 = $0.4
Final Word
To sum up, DataBrew is a brand new service that will perfectly suit people who are not comfortable with coding or simply don’t want to do it for preprocessing steps. As a first release, this nice and convenient service already looks promising and offers a satisfying experience. Using graphical tools for data preparation could become the usual way to do it in the years to come. There is no doubt that AWS Glue DataBrew will be a significant competitor.