



What is identity resolution and what challenges do we have?
Identity resolution (aka Entity resolution) is the process of determining if multiple records represent the same identity in the real world, like a Company, Person, or Place.
For example, imagine you received the name and address of some IT companies from Government records and also from a third-party data provider. In the absence of a ground truth mapping, that shows the actual linkage between these two data sources, it becomes challenging to find records belonging to the same company.
For instance, all “DataChef”, “DataChef.co”, and “DataChef (FoundersBuddy B.V.)” points to the same company where “DataChef Australia” is an entirely different company, a knowledgeable reader can differentiate them, but it’s hard to find this by simply comparing their names. This is also the case for other attributes like address, peoples’ first and last name, and even phone number where there can be some variation like including country code or “+” sign or putting country code in parenthesis.
The computational complexity is yet another major problem for identification resolution. Imagine a dataset of N records with some duplicated records that belong to the same identity. We have to make N^2 comparisons. For big datasets it becomes impossible, so we have to reduce the computation complexity by doing something called indexing methods, so we just compare records pairs that have a high possibility to be the same. Considering our company name example, you break down your dataset into subparts that each part has a company name that starts with the same letter, so you don’t need to compare records with different starting letters. This reduces computation significantly. We should define these blocking rules wisely to avoid missing potential records duplication.
A major use case of Identity resolution is resolving customer data profiles that come from different sources in an anonymous way. This can be challenging through a deterministic approach as people use different email addresses or share email addresses with other people, so a probabilistic approach can help in these situations. These tools use other data sources like IP address, location, activity time, … we try to find the same identity in our data. For more information about Identity resolution for customer data, see the Neustar video.
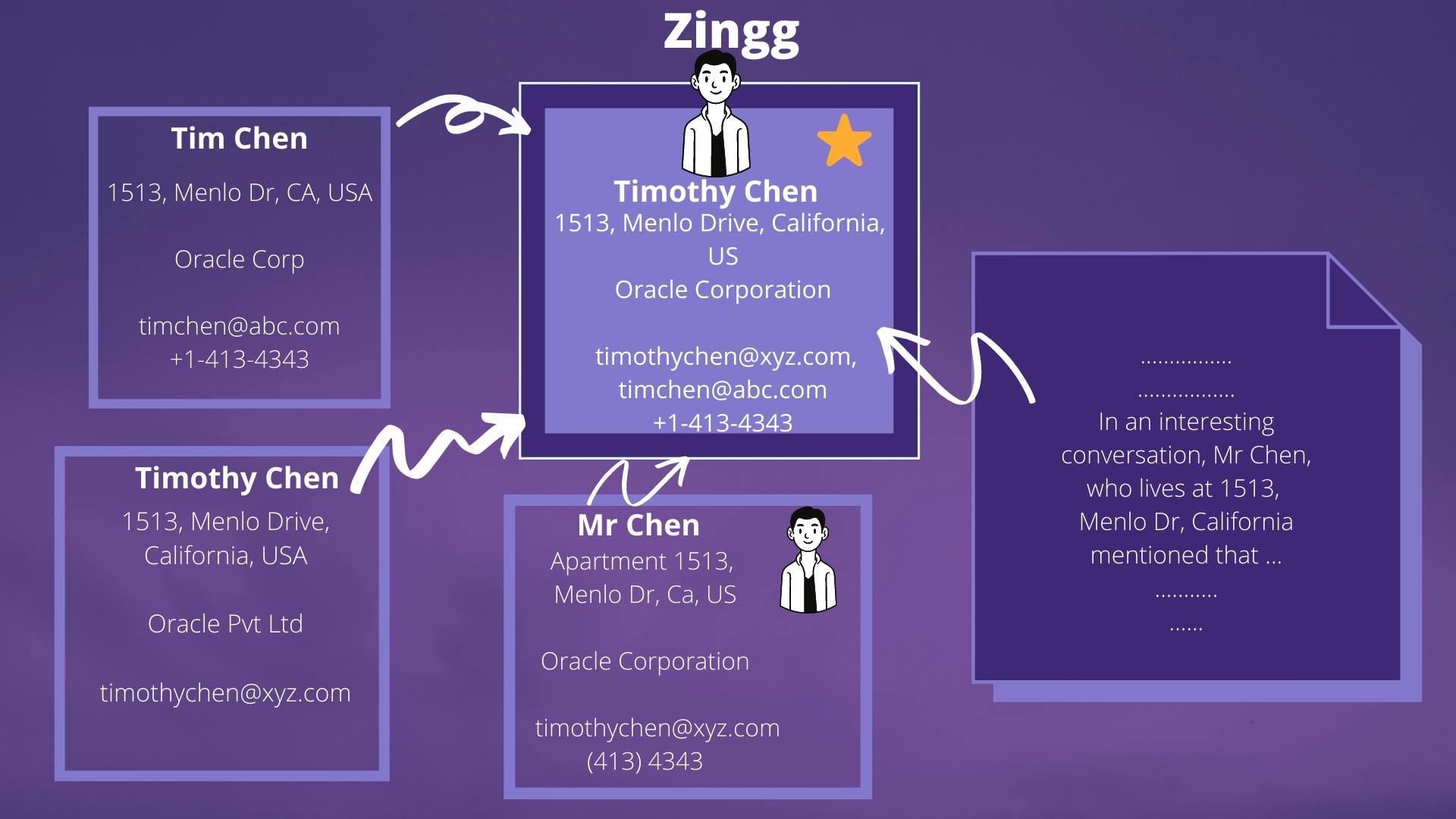
Credit: Zingg AI
In the following parts, we will review some programmatic tools that can help you with identity resolution.
What are the open source solutions?
There are plenty of open-source packages written in Python, Java, and Scala that help you with identity resolution. Each of these packages works at some scale and with different performance, so you should find your best option based on your use case.
Python packages

Dedupe is a python library that uses machine learning to perform fuzzy matching, deduplication, and identity resolution on structured data. It’s well established in the open-source community (3.2k stars on GitHub!) and also has been used by big companies like ING Bank (see their story on YouTube).
The interesting part of this tool is its active learning approach for training where you don’t need labeled data. You put your data (preferably preprocessed), and dedupe will start an active learning algorithm to find out the best approach for blocking this dataset.
It starts with asking question about pairs of records from your dataset (through an interactive terminal) and asking you to label them as match or distinct. You can finish it after a few questions (preferably at least ten matches and ten distinct record pairs). After that, it will cluster the matched records and return the output to the dataset that assigned a cluster_id to each record.
By default, parallelization (i.e., Spark) is not supported, but there is some work around it. You can also get your hands dirty with PySpark here is a blog post series that can help you.
It also offers paid support/consultancy and a web application in case you do not want to deploy it yourself under the name Dedupe.io.
It’s a python library that links records in or between data sources. It provides most of the tools needed for record linkage and deduplication. It’s more of a research tool that can be used on small and medium datasets.
Spark packages

It’s an open-source tool that can be used in a plug-and-play way. It has been written in Java and Scala. It can be run both on-premise, and on the cloud (technically anywhere with a Spark server). Spark helps with parallelization that makes it a good candidate as it can easily scale to large datasets. This package also comes with a pre-trained model so you can have a warm start.
These are two other Spark implementations of Identity resolution:
Graph-Based methods
Graph databases can be used for storing identity data. There are some tools that are built on top of these databases to perform the identity resolution.
Neo4j is a graph database that uses a specific Query Language syntax called Cypher (something like SQL but for graph databases). Neo4j has a built-in library for graph data science algorithms like identity resolution that can be used directly on its database via the Cypher syntax.
For a case study on how using graph databases can be helpful for identity resolution, read Xandr-Tech story.
Zeta Global is customer intelligent platform that collects customers data from different source and distills it down into a single view of a given customer. Zeta has been built on top of the Amazon Neptune graph database and showed to perform well at gigantic scale. See their story on the AWS re:Invent 2019.
Graph Neural Network SageMaker Jumpstart
This tool use Graph Neural Network, a branch of deep learning that showed to perform well on graph data input for various task such as node classification, edge classification and graph classification. It formalizes the problem of identity resolution to a graph’s edge classification where we want to find whether two users are connected with an edge or not (whether they are the same identity or not). This SageMaker Jumpstart that use DGL package under the hood comes as a part of Amazon SageMaker service, so you need an AWS account to use it. To get more familiar with SageMaker see our post on .
This tool needs initial training data and It’s still more of a research tool than a ready to use for prodcution.
What are the paid solutions?
It’s the paid version of dedupe, where you have more support from the core developer of the package. Dedupe.io needs your data to be on their cloud platform, so in case that’s not possible, you should go with the open-source library, but still the support is available.
Senzing is an experienced company in this field. Their tool has a kind of warm start where you don’t need initial training data, and it can do a good job with just common sense knowledge, but it can also learn in real-time to get better as your data grows.
They provide their product via two main ways:
their desktop application that’s good for low and medium datasets
Senzing API where you can access it through Python, Java, or C.
Senzing API can be deployed to AWS using AWS CloudFormation. it’s also available for on-premise usage, so you don’t send data to Senzing servers.
It is free for up to 100K records files, for bigger files, see the pricing.
Conclusion
The following table summarizes what we have shown in this post:
| Tool | Popularity * | Actively Supported | Time to Learn/Develop | Support Parallelization by Default | Need Training Data | Paid/Free |
| Dedupe | 1 | Yes | Days | No | No | Free |
| Python Record Linkage Toolkit | 3 | No | Days | No | No | Free |
| Zingg | 2 | Yes | Days | Yes | No | Free |
| SparkER | 4 | Yes | Days | Yes | ? | Free |
| JedAI | 5 | No | Days | Yes | ? | Free |
| Neo4J GDS Library | ? | Yes | Days | No | Both option | Free |
| Zeta | ? | Yes | Days | No | No | Free |
| Graph Neural Network SageMaker Jumpstart | 6 | No | Weeks | No | Yes | Free |
| Dedupe.io | 1 | Yes | Hours | No | No | Paid |
| Senzing | ? | Yes | Hours | No | No | Paid |
- Popularity for open-source packages has been calculated by the repository’s stars in GitHub.
Here we reviewed different programmatic tools for Identity resolution. There are plenty of other tools that we didn’t include here, like the ones that are part of Customer Data Platform (CDP) or fully managed SaaS solutions. Hopefully, you can now compare these tools and find the best one for your particular use case.