



What is Amundsen
Amundsen (named after the famous Norwegian polar explorer Roald Amundsen) is an open-source data discovery tool, which aims to improve the productivity of data analysts, data scientists, and engineers by enabling them to quickly find the desired datasets and their details without the need to constantly knock on the door of the usual few domain experts.
It goes beyond a simple metadata repository and provides Google-like search capabilities by indexing data resources (tables, dashboards, streams, etc.) and powering a page-rank style search based on usage patterns (e.g. highly queried tables show up earlier than less queried tables).
Through a web interface, users can search for data that is available in the organization, as well as view details about the nature of the data, such as table and column descriptions, it’s freshness, column min/max values, who owns such datasets and much more.
Amundsen makes use of the notion of data builders to extract metadata from a source and load it into a graph database, so it can be queried by the frontend. The project comes packaged with extractor logic for a number of sources, such as AWS Glue, Google BigQuery, and Delta Lake to name a few.
Databuilders are designed to be easily extensible, and custom extractors can be developed to ingest metadata from sources like Excel or Conduktor.
Use Case
For our use case, we want to deploy Amundsen in a single AWS account that is responsible for data discovery. It will host Amundsen on AWS infrastructure and will take care of running the data builder workload to extract metadata from different sources. This way, there is a single Amundsen deployment to maintain, and we can offer the service to the entire organization.
Next to the data discovery account, we have separate AWS accounts for different products. Each product account can have data sources that they want to make discoverable to the rest of the organization.
The diagram below shows a simplified design using AWS Glue catalogs as a source.
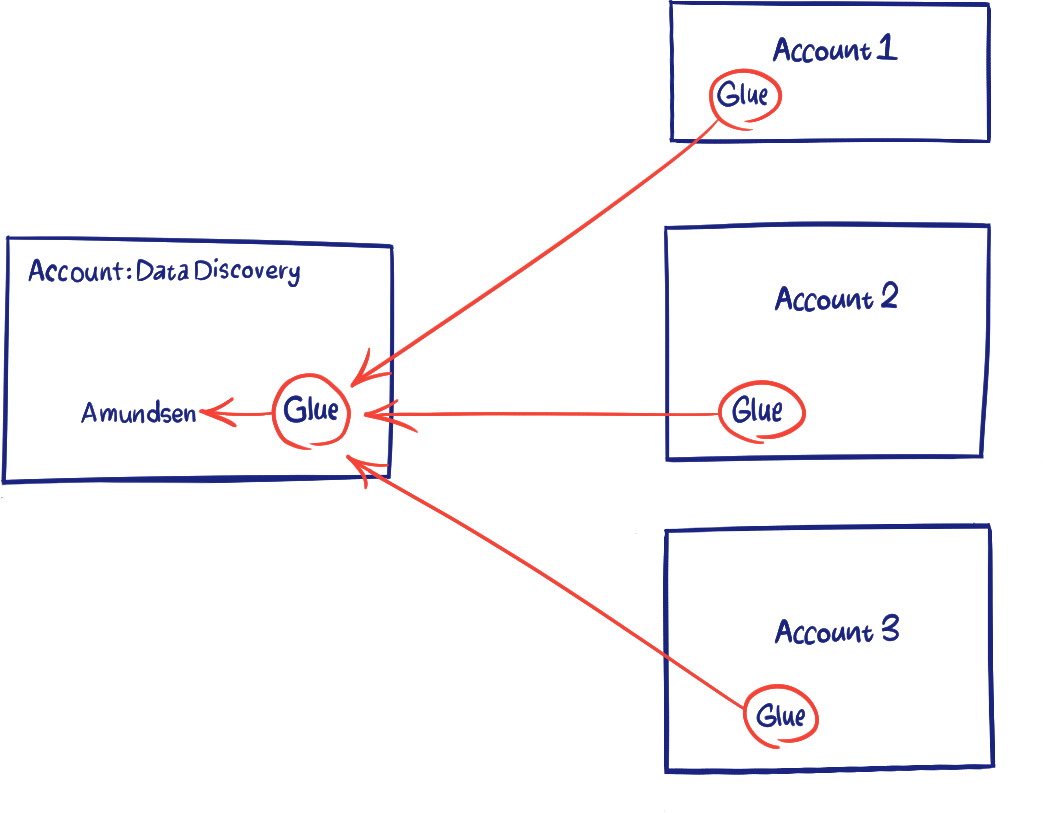
Glue as source
We wanted to take full advantage of the fact that Amundsen supports AWS Glue as a data source. A table’s metadata will appear in Amundsen as long as the Glue API call is able to list the table. This brought us to the idea to share the Glue catalog from all product accounts with one central Data Discovery account.
Sharing the catalogs with a central account, allows us to have a single Glue databuilder job that runs in the Data Discovery account and is configured to query only its Glue catalog, greatly simplifying the extraction process.
While testing this, we noticed that Amundsen’s Glue extractor logic was failing on tables shared with the DataDiscovery account (external tables). It seems that the case of external tables was not covered when the logic was initially written.
Luckily it was easy to fix this issue, and thanks to the active Amundsen community we were able to merge our fix in a couple of weeks, meaning that support for external tables should be available from the next release onwards.
Lake Formation for Access Management
For our use case, we use AWS Lake Formation for access management and cross-account resource sharing. Lake Formation makes it very easy to do access management on Glue resources. If you are used to managing permissions in a database, it will feel very natural to you. An AWS account has one or more Lake Formation administrators who are able to grant or revoke permissions on databases or tables.
Lake Formation has multiple ways of managing these permissions, either through LF-tags (recommended) or through named resources.
When sharing Glue catalog resources through the named resources method, administrators need to create a separate permission statement for each shared resource. Even though it is possible to grant the same access for ALL_TABLES in a database in one single statement, this can still become cumbersome to scale in a large enterprise with many datasets.
Using LF-tags is the recommended way to go, as you can assign such tags to resources that you want to share and then use LF-tags expressions to quickly set permissions for all tagged resources. However, the documentation provided by AWS on this topic does not go beyond setting some prerequisites and it took us a bit of trial and error to achieve a fully working setup. We don’t want you to go through the same pain, so stay tuned for a blog post on how to configure Lake Formation for cross-account sharing using LF-tags.
Conclusion
In this post, we have provided a high-level overview of how we make use of Amundsen in combination with AWS Lake Formation to provide discovery of data in Glue catalogs to our entire organization.
Stay tuned for our follow-up posts that dive into more detail on:
- how to deploy Amundsen on AWS
- how to set up cross-account sharing with Lake Formation through LF-tags